Call for Participation
With the increasing prevalence of speech-enabled applications, smart home technology has become commonplace in numerous households. For the general people, waking up and controlling smart devices is no longer a difficult task. However, individuals with dysarthria face significant challenges in utilizing these technologies due to the inherent variability in their speech. Dysarthria is a motor speech disorder commonly associated with conditions such as cerebral palsy, Parkinson’s disease, amyotrophic lateral sclerosis and stroke. Dysarthric speakers often experience pronounced difficulties in articulation, fluency, speech rate, volume, and clarity. Consequently, their speech is difficult to comprehend for commercially available smart devices. Moreover, dysarthric individuals frequently encounter additional motor impairments, further complicating their ability to manipulate household devices. As a result, voice control has emerged as an ideal solution for enabling dysarthria speakers to execute various commands, assisting them in leading simple and independent lives.
Voice wake-up serves as the primary step for operating intelligent voice-controlled devices. In light of this, we propose the Low-Resource Dysarthria Wake-Up Word Spotting (LRDWWS) Challenge, as a challenge of the IEEE SLT 2024 workshop. This challenge aims to tackle the wake-up word spotting task for individuals with dysarthria, with the ultimate goal of facilitating broader integration in real-world applications. To support this endeavor, we will release a speech dataset consisting of dysarthria wake-up words. As an initial foray into dysarthric speech, we have formulated certain guidelines to qualify the problem scope and concentrate on the distinctive characteristics of the dysarthric wake-up word spotting task.
- Controlled Environment: Given the intricate speech patterns exhibited by dysarthric individuals, meticulous efforts were made to minimize potential interferences during the audio recording process. Specifically, the recordings were conducted in a controlled environment carefully chosen to be devoid of any background noise.
- Speaker-dependent: Inaccurate pronunciation and reduced fluency exhibited by individuals with dysarthria lead to substantial variability in their speech. Even among individuals with the same type of dysarthria, the pronunciation of a single word can vary under different conditions. Hence, this challenge aims to address the speaker-dependent wake-up word spotting, offering a promising solution to voice wake-up problem among dysarthria speakers.
- Limited Samples: Individuals with dysarthria often have trouble in recording lengthy audio due to physical limitations. From the perspective of practical application, this challenge allows the use of only a limited number of wake-up word audio samples from a specific dysarthria patient. However, we will provide additional wake-up word audio samples and non-wake-up audio samples from both ordinary individuals and those with dysarthria as supplementary data.
This challenge seeks to solve speaker-dependent wake-up spotting tasks by utilizing a small amount of wake-up word audio of the specific person. This research has the potential to not only enhance the quality of life for individuals with dysarthria, but also facilitate smart devices in better accommodating diverse user requirements, making it a truly universal technology. We hope that the challenge will raise awareness about dysarthria and encourage greater participation in related research endeavors. By doing so, we are committed to promoting awareness and understanding of dysarthria in society and eliminating discrimination and prejudice against people with dysarthria.
Task
The goal of this task is to develop a speaker-dependent dysarthria wake-up word spotting system that performs well according to the evaluation criteria. Participants should use the enrollment utterances from the target speakers (approximately 3 minutes per person, including wake-up and non-wake-up words), as well as speech data from other individuals with dysarthria, to train the system. Note that we do not restrict the usage of other relevant open-source datasets (which should be explicitly stated in the final paper or technical report).
Evaluation
The combination of False Reject Rate (FRR) and False Alarm Rate (FAR) is adopted as the evaluation criterion, which is defined as follows:
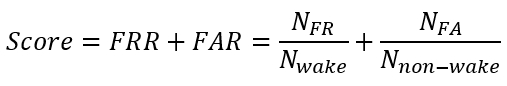
where Nwake and Nnon-wake denote the number of samples with and without wake-up words in the evaluation set, respectively. NFR denotes the number of samples containing the wake-up word while not recognized by the system. NFA denotes the number of samples containing no wake words while predicted to be positive by the system. The lower Score, the better the system performance.
The evaluation toolkit can be downloaded from [Here].
Dataset
The dataset includes 18,630 recordings totaling 17 hours, of which 10,125 are from non-dysarthric recordings (Control) totaling 7.6 hours, and 8,505 are from dysarthric recordings (Dysarthria) totaling 9.4 hours. We record utterances from 21 dysarthric (12 females, 9 males) and 25 non-dysarthric (13 females, 12 males) speakers. The participants with dysarthric speakers have the following characteristics:
- Mandarin nature speakers;
- Broad age distribution (range from 18 to 55) and gender balance;
- Diverse etiologies contribute to dysarthria, including cerebral palsy and hepatolenticular degeneration;
The speaker numbers of the training and development partitions can be found in Table 1.
| Control | Dysarthria | |
|---|---|---|
| Train | 25 | 17 |
| Dev | 0 | 4 |
| Sum | 25 | 21 |
The test set will be provided separately soon, expected to include speech data from 10 individuals with dysarthria. The recording standards and data format will be consistent with the development set.
In addition, the intelligibility evaluation is provided of each dysarthria recorder, which entails the transcription of recordings by five expert annotators who compare them against the standard text in the corpus. Each annotator calculates the percentage of accurately transcribed words, and the average of these five values is used to derive the intelligibility score for each dysarthric speaker. We define the results evaluated by annotation accuracy as subjective intelligibility.

Note that there is no limitation on use of datasets for the challenge. The other datasets we recommend are:
(1) Speech recognition dataset for dysarthria:
- CDSD(Mandarin Chinese): https://arxiv.org/abs/2310.15930
- Torgo(English): https://springer.dosf.top/article/10.1007/s10579-011-9145-0
- UASpeech(English): http://www.isle.illinois.edu/sst/data/UASpeech/
(2) Keyword spotting dataset for non-dysarthria:
- Hey Snip: https://github.com/sonos/keyword-spotting-research-datasets
- Google Speech Command: https://arxiv.org/pdf/1804.03209.pdf
- Hi Miya: http://www.aishelltech.com/wakeup_data
- Hi Xiaowen: http://openslr.org/87/
Rules
- The use of the evaluation set of the test set in any form of non-compliance is strictly prohibited, including but not limited to use it to fine-tune or train model.
- Any resource is permitted to be used to improve the results. All the external public datasets used should be clearly indicated in the final report.
- If the scores of the two teams on the test data set are the same, the system with lower computation complexity will be judged as the superior one.
- The right of final interpretation solely belongs to the organizer. In case of special circumstances, the organizer will coordinate the interpretation.
Participants are encouraged to prioritize technological innovation, particularly the exploration of novel model architectures, rather than relying solely on increased data usage.
Registration
Participants must sign up for an evaluation account where they can perform various activities such as registering for the evaluation, as well as uploading the submission and system description.
The registration email must be sent from an official institutional or company email address (e.g., edu.cn); a public email address (e.g., 163.com, qq.com, or gmail.com) is not accepted.
Once the account has been created, the registration can be performed online. The registration is free to all individuals and institutes. The regular case is that the registration takes effect immediately, but the organizers may check the registration information and ask the participants to provide additional information to validate the registration.
To sign up for an evaluation account, please click Quick Registration.
Submission and Leaderboard
Participants should submit their results via the submission system. Once the submission is completed, it will be shown in the Leaderboard, and all participants can check their positions.
For each test set, participants can submit their results no more than 3 times a day.
The leaderboard will now be divided into two sections: leaderboard-A and leaderboard-B.
The evaluation data with released labels from the test set(Test-A) will be used for the leaderboard-A. While participants have access to the corresponding labels, it is strictly prohibited to utilize these labels to enhance their models during the training phase. The leaderboard-A will be open for submissions from May 13th to May 28th. The purpose of the A-board is to familiarize participants with the submission process and adjust their models based on the results of the A-board. The scores from the A-board will NOT be included in the final ranking of the competition.
Subsequently, a separate dataset(Test-B) will be provided for the leaderboard-B, comprising labeled enrollment data and unlabeled evaluation data. There are no restrictions on utilizing all the data from the A-board during the training phase for the B-board. The leaderboard-B will become accessible once the leaderboard-A period concludes and will remain open from May 29th to June 1st. Participants should submit results for the B-board within a short period of time. There won't be sufficient time available on the B-board to make big adjustments to model.
The final scores will ONLY be based on leaderboard-B.
Timeline (AOE Time)
- April 7th, 2024 : Registration opens.
- April 10th, 2024 : Training set release.
- April 20th, 2024 : Development set and baseline system release.
- May 13th, 2024 : Test sets A audio release and leaderboard-A open.
- May 28th, 2024 : Leaderboard-A freeze.
- May 29th, 2024 : Test sets B audio release and leaderboard-B open.
- June 1st, 2024 : Leaderboard-B freeze. (2024/6/1, 0:00, AM, AOE)
- June 20th, 2024 : Paper submission deadline.
Organizers
- Jun Du, University of Science and Technology of China, China (jundu@ustc.edu.cn)
- Hui Bu, Beijing AIShell Technology Co. Ltd, China (buhui@aishelldata.com)
- Ming Li, Duke Kunshan University, China (ming.li369@dukekunshan.edu.cn)
- Ming Gao, University of Science and Technology of China, China (vivigreeeen@mail.ustc.edu.cn)
- Hang Chen, University of Science and Technology of China, China (ch199703@mail.ustc.edu.cn)
- Xin Xu, Beijing AISHELL Technology Co., Ltd., China (xuxin@aishelldata.com)
- Hongxiao Guo, Beijing AISHELL Technology Co., Ltd., China (guohongxiao@aishelldata.com)
- Chin-Hui Lee, Georgia Institute of Technology, USA (chl@ece.gatech.edu)





Please contact e-mail lrdwws_challenge@aishelldata.com if you have any queries.
